Katara’s MCP Server Does It For You (With 9 Ready-to-Use Tools)
If you're a developer (especially a prompt-first one) trying to ship agentic applications in 2026, you already know the pain:
- Ingesting docs / websites / GitHub / Notion is fiddly
- Chunking + embedding + indexing feels like plumbing
- Keeping data fresh is manual and error-prone
- Asking meaningful questions over your content still requires glue code
Most teams waste weeks (sometimes months) on this infrastructure before they can even start building real agents.
Katara changes that equation.
Our MCP-powered server (Model Context Protocol) gives you a managed, production-ready data ingestion + Q&A layer that plugs straight into your IDE workflow (Cursor, Zed, Claude Code, anything ACP-compatible) and lets you focus on agent logic instead of ETL nightmares.
Today we’re opening the hood on the 9 core tools already live in the Katara MCP server and showing you exactly how to use them to go from zero knowledge base → working Q&A in under 10 minutes.
The 9 Tools You Actually Get (No Custom Code Required)
| Category |
Tool |
What it does (real value) |
| Agent Mgmt |
list_agents |
See every agent running in your org (great for debugging multi-agent setups) |
| Agent Mgmt |
get_agent |
Inspect config, status, memory & last runs of any agent |
| Ingestion |
ingest_website |
One sentence → live website loader + scraper (depth, schedule, filters) |
| Ingestion |
list_loader_agents |
Inventory of all your Website / GitHub / Notion loaders |
| Ingestion |
run_loader_agent |
Manually refresh any loader (re-scrape, re-pull PRs/issues) |
| Ingestion |
get_run_status |
Real-time job status (critical when datasets are large) |
| Ingestion |
sync_collection |
Chunk → embed → index → make everything instantly searchable |
| Ingestion |
update_loader_agent |
Change depth, schedule, enabled/disabled — zero downtime |
| Q&A |
ask_question |
Ask natural-language questions → grounded answers + sources |
That's it. Nine commands. Full lifecycle: ingest → refresh → sync → query.
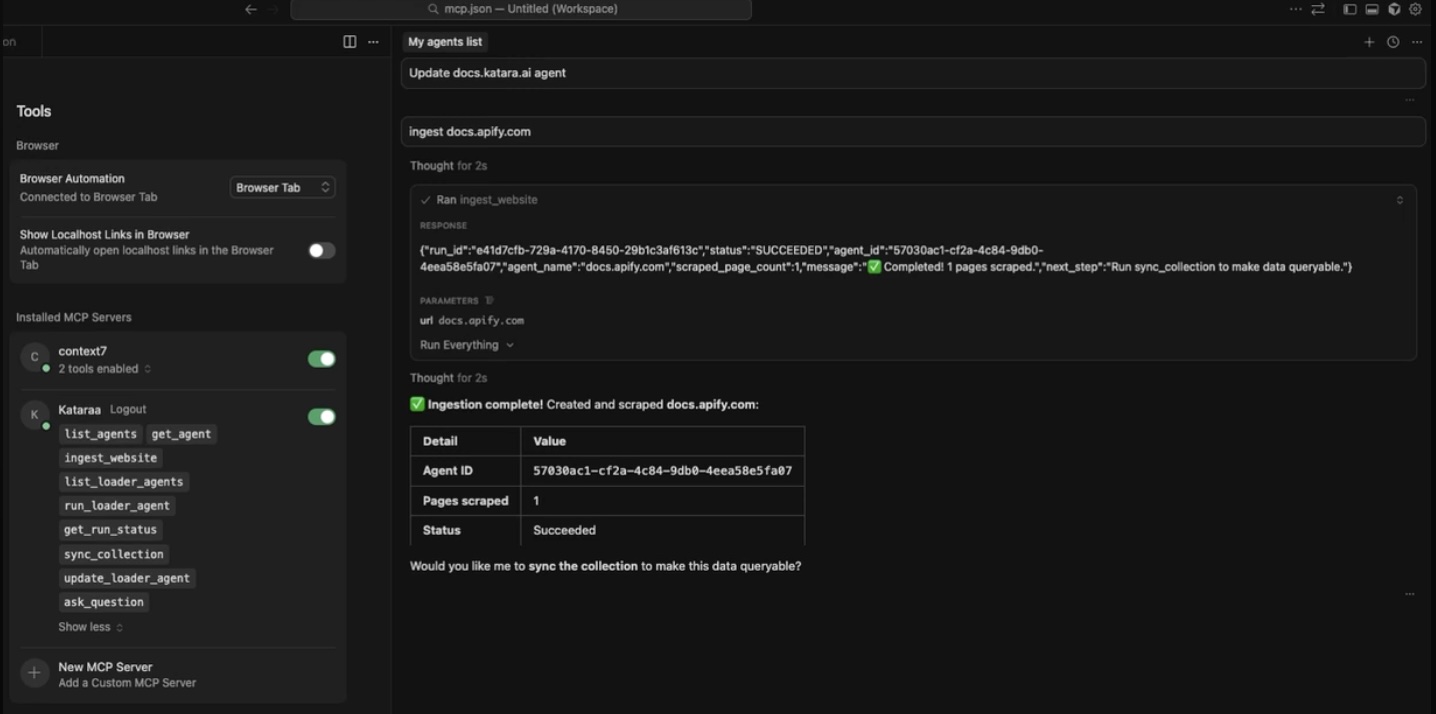
Real Example: Ingest Docs → Ask Questions in ~7 Minutes
You (in chat): Ingest https://docs.myproduct.com
→ Katara shows interactive form (smart defaults filled):
• URL: https://docs.myproduct.com
• Name: myproduct-docs
• Max depth: 2
• Schedule: daily
You: change depth to 3 → click "Create & Start"
Progress (real-time in UI):
🌐 Starting scrape for myproduct-docs...
📄 Scraping... (5 pages) → (12 pages) → (47 pages)
🔍 Discovering pages...
📝 Extracting content...
✅ Scraping complete! (47 pages)
You: Sync the collection
→ Quick Yes/No confirmation → click Sync
Progress:
⚙️ Starting collection sync...
⚙️ Processing documents...
🧠 Generating embeddings...
📦 Updating index...
✅ Collection synced! Ready for questions.
You: What authentication methods does myproduct support?
→ Katara returns precise answer + clickable sources from your docs
Same flow works for GitHub repos (issues + PRs + code) and Notion workspaces.
Common Workflows That Ship Fast With These Tools
- Fresh docs Q&A bot Ingest website → daily schedule → sync on cron → expose ask_question via your agent
- Live GitHub knowledge base ingest_website on /docs + run_loader_agent on main repo → developers ask “how do we deploy X?” with up-to-date code + issues
- Regulatory / compliance answers grounded in policy docs Ingest Notion policy pages → ask_question with guardrails → audit trail via sources
- Quick refresh before demo / customer call “Run the api-docs loader” → “Sync” → instant fresh answers
Why This Matters (Our North Star)
Most agentic products die in the infrastructure swamp not because the agent logic is bad, but because builders spend 60–80% of time on ingestion, chunking, re-indexing, rate-limits, and stale data.
Katara MCP server removes ~80% of that work:
- Zero server provisioning
- Built-in progress tracking & error surfacing
- Interactive forms instead of YAML hell
- Automatic sync → query-ready in one step
- Works with Cursor/Zed/any ACP editor → context already in your IDE
Result: You can sign up, ingest your first dataset, and demo a working agentic Q&A experience same day.
Quick Tips From Teams Already Using It
- Always sync after ingestion, data isn’t queryable until you do
- Use list_loader_agents before creating new ones (prevents duplicates)
- Forms remember smart defaults changing depth/schedule takes 5 seconds
- Watch the emoji progress messages they tell you exactly where you are
- Need to disable old loaders? Just update → uncheck Enabled
Ready to Skip the Plumbing?
We’re in public beta (limited spots — no credit card to start).
→ Join the beta
Once you're in:
- Connect your IDE (Cursor recommended instant context)
- Say “Ingest [your docs URL]”
- Sync
- Ask real questions
- Ship faster
The faster you stop building boring RAG infrastructure, the faster you can build the actual agentic product your customers will pay for.
Let’s get you to your first milestone together.
See you in the beta.